

Let’s talk about DINOv2, a paper that takes a major leap forward in the quest for general-purpose visual features in computer vision. Inspired by the success of large-scale self-supervised models in NLP (think GPTs and T5), the authors at Meta have built a visual foundation model that learns without any labels and still outperforms some of the best text-supervised alternatives like OpenCLIP on a wide range of image and pixel-level tasks. Cool, right?
The main idea is to create a vision model whose features work “out of the box” across many tasks and datasets, just like how you might use a frozen LLM for downstream NLP tasks. This means no need to fine-tune on a downstream dataset – you just extract features and slap a linear layer on top.
Model Architecture
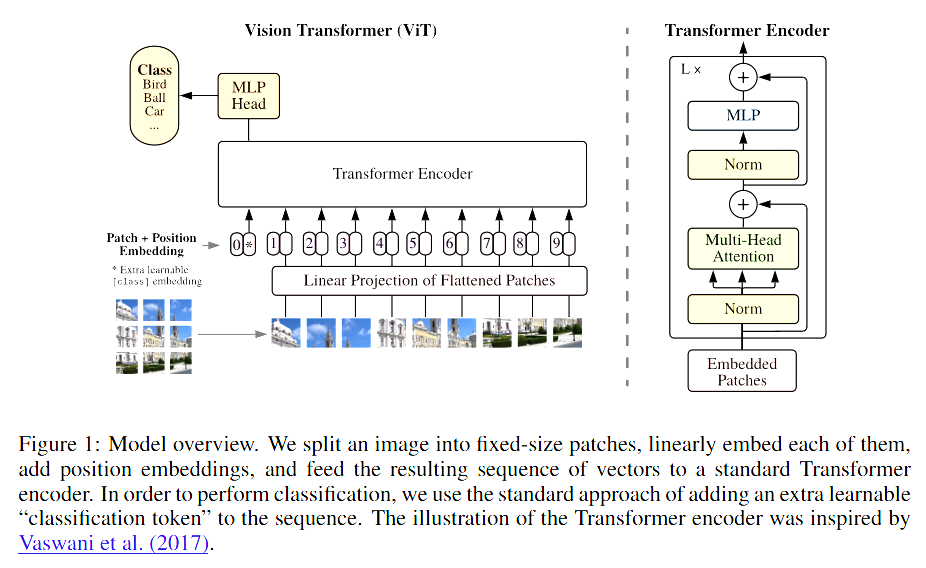
The backbone of DINOv2 is the Vision Transformer (ViT) architecture (shown in figure 1), which was originally proposed by Dosovitskiy et al., 2021. DINOv2 explores multiple sizes of ViTs, including:
- ViT-S/14 (small)
- ViT-B/14 (base)
- ViT-L/14 (large)
- ViT-g/14 (giant)
All of these use a patch size of 14×14, which means the input image is divided into non-overlapping patches that are then linearly embedded, just like tokens in an LLM.
The first key architectural element is the Patch Embedding Layer, which takes the input image, splits it into fixed-size patches, and projects each of these patches into a linear embedding space. This embedding allows the model to treat image patches like tokens in a sequence, essentially turning the image processing problem into a sequence modeling task.
Next are the Positional Encodings, crucial for retaining spatial information. Since the transformer sees patches as an unordered set, positional encodings are added to help the model understand the relative positions of these patches within the original image structure. Without this, the model would lose valuable spatial context.
At the heart of the ViT architecture lie the stacked Transformer Encoder Blocks. Each encoder block consists of multi-head self-attention layers, followed by Multi-Layer Perceptron (MLP) layers and normalization layers. These blocks are stacked multiple times – 12, 24, or even more – depending on the model size. This stacking allows the model to capture increasingly complex patterns and hierarchical features from the input patches.
The ViT model also utilizes a special token known as the CLS Token. This token is prepended to the sequence of embedded patches and serves as an aggregate representation for the entire image. After passing through all transformer encoder layers, the final embedding of this CLS token is used as a global image representation for downstream tasks.
What sets DINOv2 apart from standard ViT training is its teacher-student self-distillation method for self-supervised learning. Here, the student network undergoes gradient-based updates during training, whereas the teacher network represents an Exponential Moving Average (EMA) of the student network. Both networks receive multiple augmented views (global and local crops) of the same image. The student network learns by trying to match the outputs of the teacher network on corresponding views, ensuring consistent feature extraction across various augmentations.
Training Optimizations
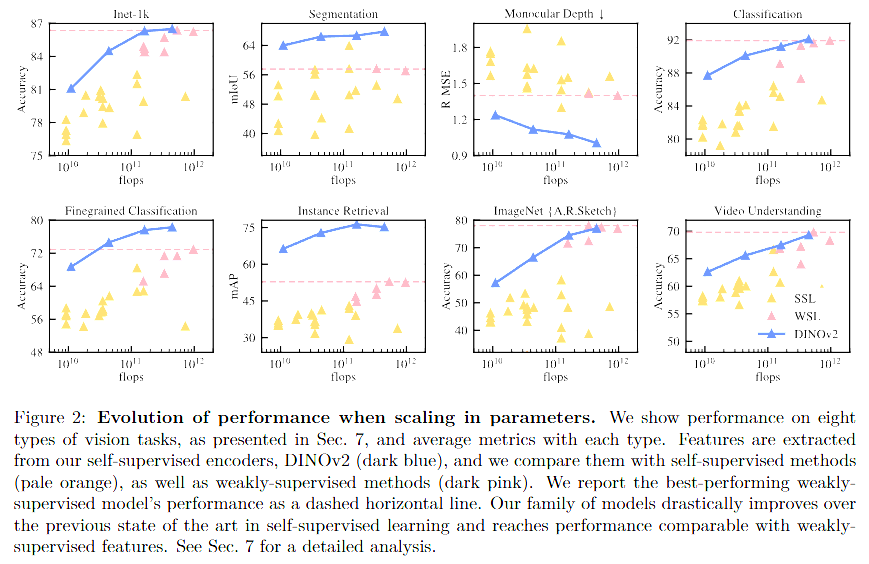
This figure shows how both more data and larger model sizes directly correlate with better performance across downstream tasks. Bigger is still better – but only if you can train stably. To stabilize training at large scales, the authors implemented several key optimizations. First, LayerScale was introduced, applying a learnable scaling factor to the residual connections within transformer layers. This simple yet effective tweak prevents the network from collapsing during training, especially as model depth and size increase significantly.
Another key optimization in DINOv2 lies in its suite of efficient training strategies designed to stabilize and accelerate model training at scale. The authors implement a range of improvements -including a custom, fast and memory-efficient attention mechanism inspired by FlashAttention, sequence packing that enables simultaneous processing of both large and small image crops, and an optimized stochastic depth implementation that skips computations for dropped residuals.
DINOv2 also leverages efficient augmentations such as aggressive random cropping, color jittering, and Gaussian blur. These augmentations ensure that the model sees diverse views of each image, enhancing its robustness and encouraging it to capture invariant representations that generalize well across different image distributions.
All models within the DINOv2 family are trained using a purely self-supervised objective, meaning no explicit labels are required at any point during training. Furthermore, a distillation process enables smaller ViT models to benefit from the rich knowledge embedded within the largest ViT-g/14 model, effectively transferring its superior capabilities to more efficient versions.

The above figure shows that distilling from the large ViT-g/14 into smaller models helps retain most of the performance while drastically reducing compute. This also enables deployment of DINOv2 features in low-latency applications.
No Supervision
Unlike OpenCLIP or ALIGN, which rely on natural language to guide vision models, DINOv2 is fully self-supervised. That means it doesn’t rely on noisy text-image pairs scraped from the web. Despite that, it outperforms these models in many benchmarks.
So how does it achieve that?
DINOv2 achieves its impressive performance through a carefully crafted training strategy that combines several components. At its core, it employs a teacher-student framework where the teacher network – maintained as an exponential moving average of the student – provides stable targets to guide learning. Both networks are fed diverse views of the same image through multi-crop augmentations, ensuring that the model learns robust features that remain consistent across different scales and perspectives.
Moreover, DINOv2 leverages Vision Transformer-specific techniques such as layer scaling, which introduces learnable scaling factors to the residual connections to further improve training stability, and other architectural adjustments tailored for ViTs. These combined innovations enable DINOv2 to learn general-purpose visual features from large-scale, uncurated data, ultimately leading to state-of-the-art performance across a wide range of vision tasks.
Results
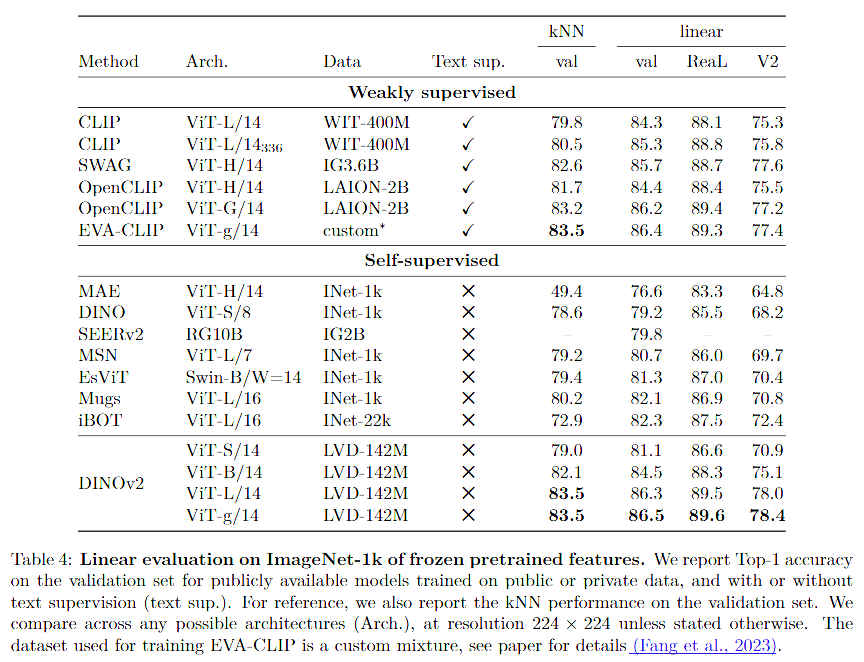
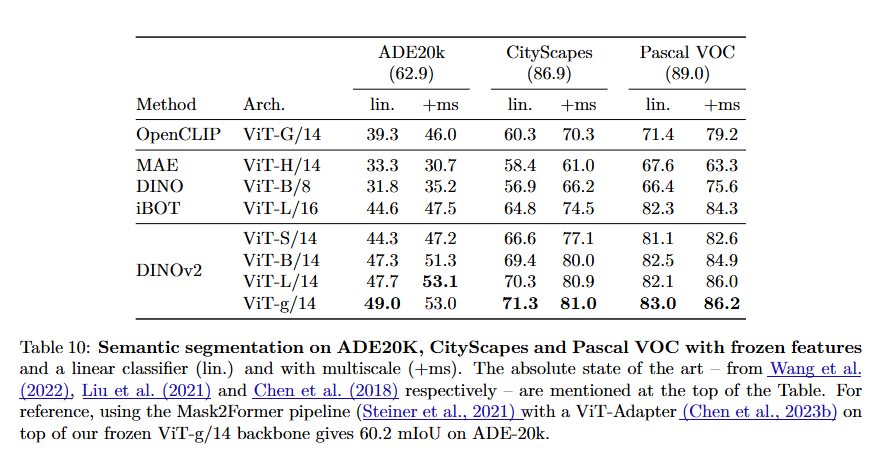
Across datasets like ImageNet-1k, ADE20K, COCO, and semantic segmentation benchmarks, DINOv2 features consistently outperform OpenCLIP, especially at the pixel level. What’s more? They hold up even when used without fine-tuning.
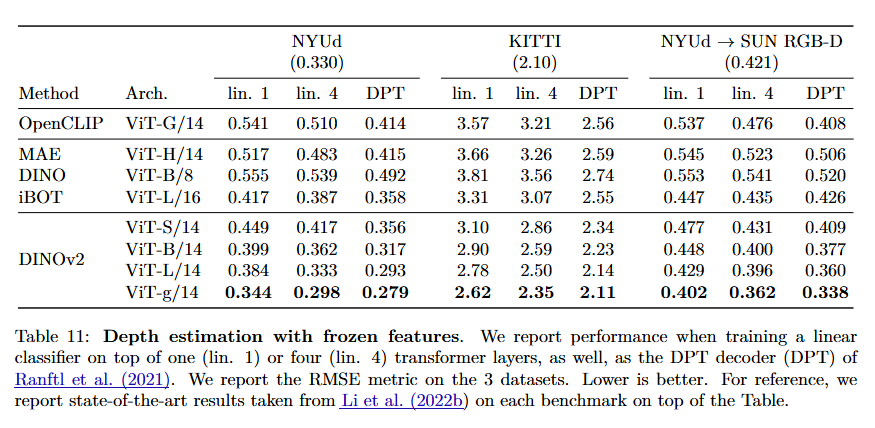
In addition, DINOv2 demonstrates the power of self-supervised learning to capture rich visual representations at both global and local levels. Extensive experiments in the paper show that the learned features excel not only in image-level tasks like classification but also in fine-grained, pixel-level tasks such as segmentation and depth estimation. This ability to capture intricate details and spatial structures underscores the model’s versatility, providing a robust foundation for a wide range of vision applications – all achieved without relying on external text supervision.
All in all, DINOv2 is a big step toward GPT-like foundation models in vision. If you’re building anything with visual features, this is a paper worth bookmarking — and a model worth trying. You can read the complete paper here.
Bravo Meta team, this one is a banger.


