

Scaling Supervision Instead of the Architecture
Depth Anything doesn’t try to win monocular depth with a clever new backbone. It asks a simpler question: if you can cheaply manufacture supervision at Internet scale, can a very plain recipe become a foundation model? The authors pair ~1.5M labeled frames with an additional ~62M unlabeled images, generate pseudo-labels with a competent teacher, and then retrain a student on the mix while carefully avoiding leakage from standard benchmarks like NYUv2 and KITTI so the zero-shot story is clean.
The Architecture
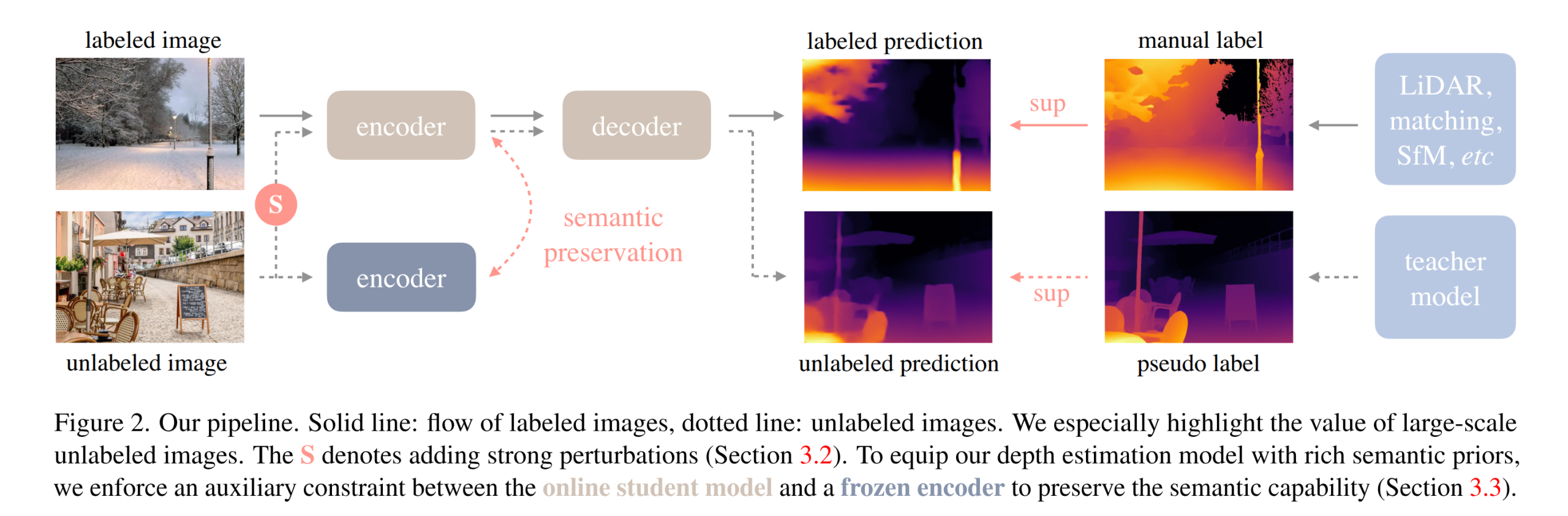
The most interesting part is that naive self-training didn’t help once the labeled base was strong; the student just mirrored the teacher’s blind spots. The fix is to make the unlabeled objective genuinely harder. During training the student sees unlabeled images with aggressive color jitter and blur, and half the time those frames are CutMixed with another image. The teacher, used to produce the targets, always sees clean inputs. That asymmetry forces the student to learn invariances instead of overfitting to the teacher’s exact predictions, and it’s the hinge that turns “62M more of the same” into actual signal. They also re-initialize the student rather than fine-tune from the teacher – a small detail that leads to a big effect.
There’s a second move that reads obvious in hindsight: keep semantics rich without detouring through a segmentation head. They tried the segmentation route: RAM + GroundingDINO + HQ-SAM to mint 4k classes – and it didn’t budge depth. Discrete masks threw away too much of the scene signal. The alternative that worked was feature alignment: nudge the student’s intermediate features toward frozen DINOv2 features using a cosine loss, with a tolerance margin so you stop aligning pixels once they’re “semantically close enough.” That margin matters; push too hard and you smear away the part-level gradients depth actually needs.
Results
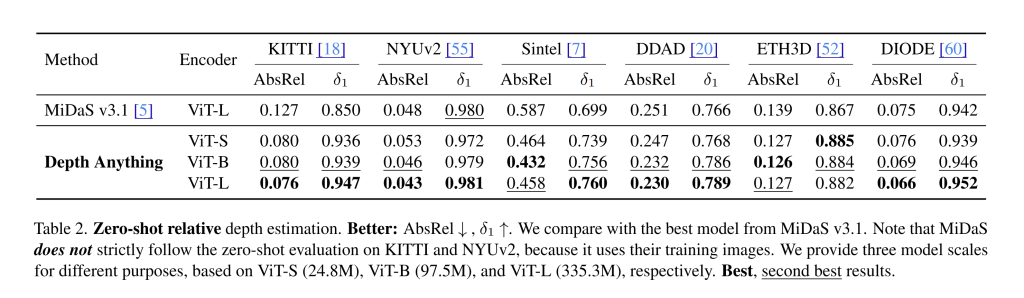
Does the boring recipe pay off? On six unseen datasets, Depth Anything with a ViT-L encoder beats MiDaS v3.1 at zero-shot relative depth, including a clean jump on DDAD (AbsRel 0.251→0.230; δ1 0.766→0.789). Even the smaller ViT-B and ViT-S models hold up surprisingly well, which is a nice tell that the training story is doing the work. Note the authors also call out that MiDaS trained on NYUv2/KITTI, so its wins there are not strictly zero-shot; Depth Anything deliberately keeps those out of pretraining.
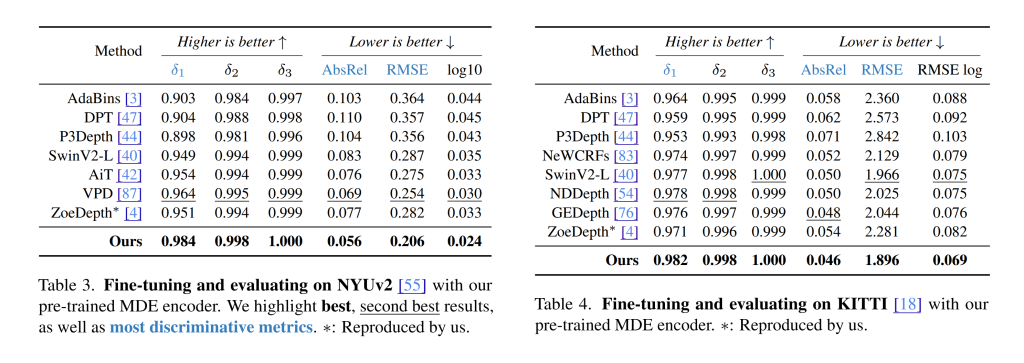
Fine-tuning behaves the way you’d hope a “foundation” model would. Swap their encoder into ZoeDepth, keep the decoder simple, and you get new highs on NYUv2 (δ1 0.984, AbsRel 0.056) and improvements on KITTI, without exotic alterations to the downstream recipe. That’s the practical win: you can adopt the encoder and see benefits without tearing up your stack.
A few implementation choices ground the claims. Pretraining runs at a short-side of 518 px and preserves aspect ratio, which is conservative but fast; zero-shot evaluation follows MiDaS with scale/shift alignment. It’s all very reproduce-able and, importantly, gets the results without heavyweight engineering.
So where are the edges? Two ceilings are obvious from the paper itself: the largest public checkpoint is only ViT-Large, and the common 512-ish training resolution is a limiter for fine geometry. The authors say they plan to scale to ViT-G and push resolution upward, which should further de-bias the teacher and sharpen spatial detail. I’d also love to see them diversify the teacher signal to keep the student from inheriting systematic errors.

Overall, Depth Anything moves the frontier by respecting two unglamorous truths: data diversity beats architecture gymnastics, and unlabeled data only helps if you make the objective bite. The paper doesn’t chase novelty for its own sake; it sharpens a well-worn pipeline until it behaves like a foundation model.


