

Motivation
Autonomous vehicles rely on different sensors (cameras, LiDAR, and radar) each offering a unique view of the world. Combining them is key to reliable perception, but it’s tricky because cameras capture 2D images while LiDAR gives 3D structure. Earlier methods tried to force one into the other’s frame, but that always loses something. Projecting 3D points into 2D distorts depth, while mapping image features onto sparse LiDAR throws away rich visual detail. Simple “late-fusion” approaches that just merge final detections also fall short, since they miss the chance to reason jointly over deeper features.
Recent methods often paint image features onto LiDAR points before running a LiDAR-based detector. This works decently for 3D object detection, but it’s narrow, focused only on object points and geometry, while ignoring the broader image context. The camera-to-LiDAR mapping is also very sparse: with a 32-beam LiDAR, only ~5% of pixels get used, so most image information is lost. This “semantic loss” makes point-level fusion weak for segmentation or other tasks that need dense semantics. It also assumes LiDAR is always the primary sensor, which fails if the LiDAR is sparse or degraded. In short, these methods lack a true shared representation that captures both camera semantics and LiDAR geometry.
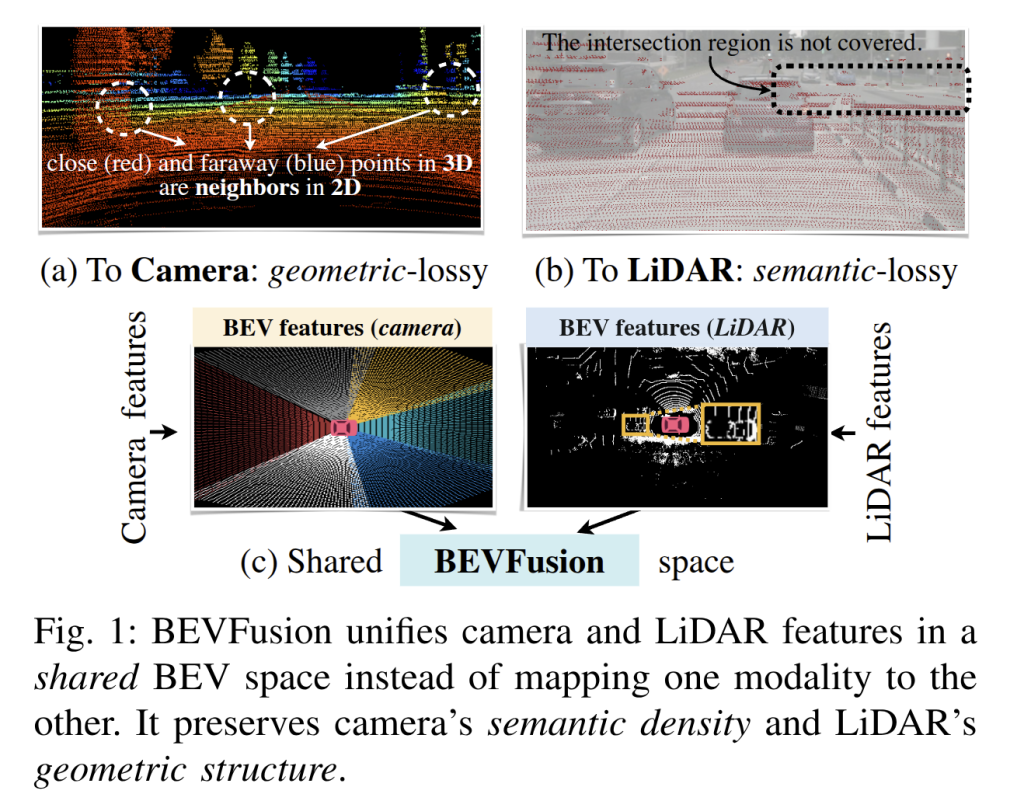
BEVFusion takes a different route: it brings both camera and LiDAR features into a shared Bird’s-Eye View (BEV). The top-down view is a natural fit since most 3D tasks, like detection or free-space segmentation, are defined on the ground plane. In BEV, cameras keep their rich semantic detail and LiDAR keeps its precise geometry, combined in one space. Instead of discarding information during projection, all camera pixels are lifted into the plane and LiDAR features are flattened, creating a joint BEV feature map. This setup is task-agnostic, handling both foreground and background, and works across detection, segmentation, and more. The main challenge was speed: lifting millions of pixels to 3D is slow (over 500 ms per frame in early tests). BEVFusion’s key advance is making this efficient, turning the idea into a practical, multi-sensor, multi-task framework.
BEVFusion Architecture Overview
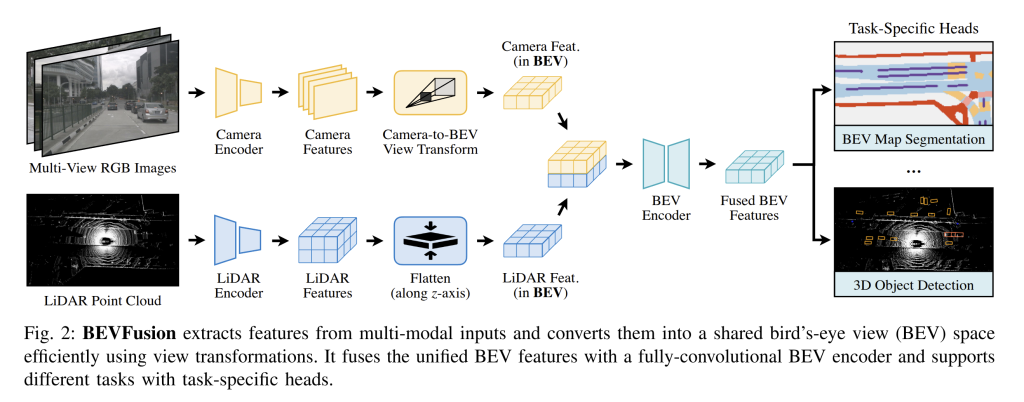
The BEVFusion architecture is modular, with five main parts:
Encoders: Cameras use a 2D backbone (like ResNet or a transformer) to extract feature maps, while LiDAR uses a 3D sparse CNN or pillar-based network to produce a BEV-style pseudo-image. Each works in its native space.
Camera-to-BEV Transformation: Image features are “lifted” into 3D using a depth distribution along each camera ray, then pooled into a BEV grid. This preserves dense image semantics instead of discarding most pixels, unlike point-level fusion. LiDAR features, already 3D, are simply flattened into BEV.
Multi-Modal BEV Fusion: With both modalities in BEV, fusion is easy—just concatenate along the channel dimension. The design is simple and extensible, so other sensors (like radar) could be added the same way.
BEV Encoder: A fully convolutional backbone refines the fused BEV map, smoothing out errors from depth prediction or calibration. It efficiently mixes camera semantics with LiDAR geometry.
Task Heads: Finally, task-specific heads branch off. The paper demonstrates two: a detection head (predicting 3D boxes from BEV heatmaps, à la CenterPoint) and a segmentation head (predicting drivable areas, crosswalks, lanes, etc.). Since everything is in BEV, multi-task learning comes almost for free.
The big hurdle was efficiency: naively pooling millions of image features into BEV took over 500 ms per frame. The authors solved this with key optimizations, enabling BEVFusion to run in practice.
Efficient BEV Pooling
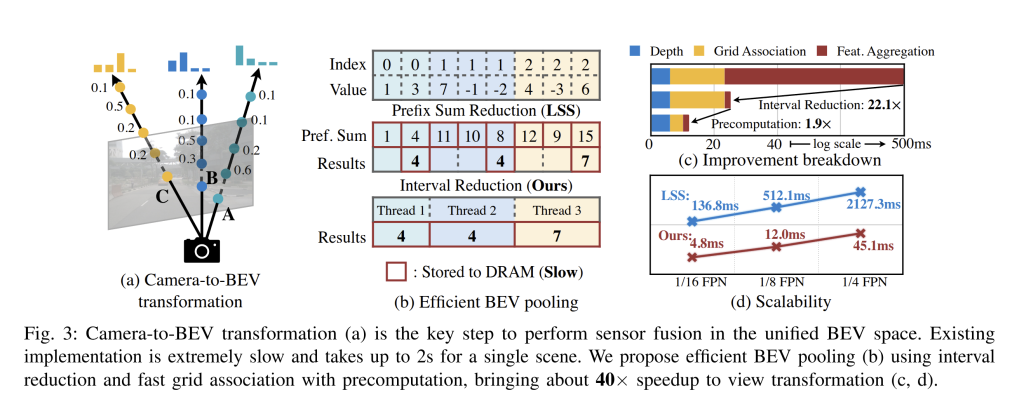
Efficiently transforming multi-camera features into BEV was the biggest hurdle for BEVFusion, with pooling alone taking more than 80% of runtime in early tests. To fix this, the authors redesigned the pooling step with two key ideas: precomputation and interval reduction. Together, these changes delivered more than a 40× speedup and turned what was once the slowest part of the pipeline into a minor cost.
The first improvement came from precomputing projection indices. Normally, for every frame, the system would need to calculate where each pixel–depth pair lands in the BEV grid. But that mapping depends only on calibration and discretization, which are fixed. By caching the mapping once offline, the model can simply look up indices at runtime. This reduced the grid assignment cost from about 17 ms to just 4 ms.
The second breakthrough was in feature aggregation. Earlier approaches relied on prefix-sum scans, which were GPU-unfriendly and extremely slow, nearly 500 ms per frame. BEVFusion introduced a custom kernel that assigns one thread per BEV cell and directly accumulates the features belonging to it. This eliminated costly synchronization and cut aggregation to just 2 ms, a 250× speedup for that step alone.
With both optimizations in place, the camera-to-BEV pooling dropped from over 500 ms to about 12 ms per frame. What used to consume most of the runtime now takes only about 10%. Importantly, these gains come without approximation, the pooling remains exact and scalable across resolutions. This technical advance is what made BEV fusion practical in near real time, enabling the strong results reported later in the paper.
3D Object Detection Performance
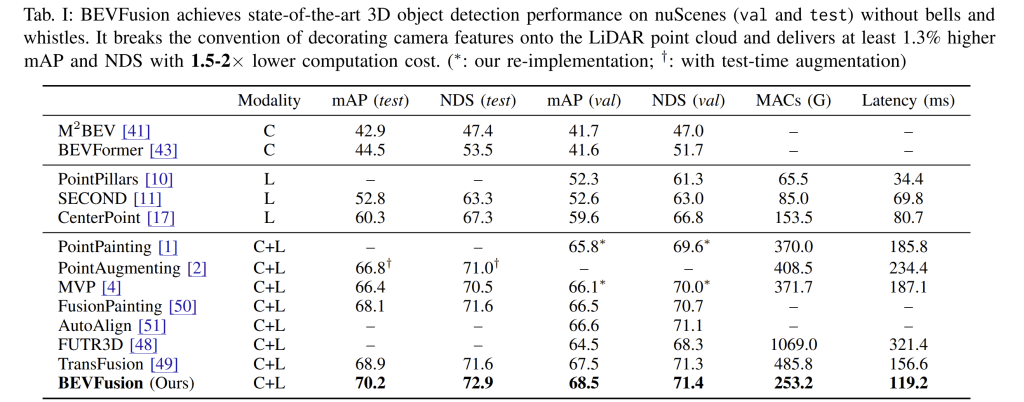
On the nuScenes benchmark, BEVFusion set a new standard for both accuracy and efficiency. Without relying on tricks like test-time augmentation or ensembling, it reached 70.2% mAP and 72.9% NDS, about 1.3% better than the previous best method, TransFusion. What makes this more impressive is that it also ran faster: 8.4 FPS on an RTX3090, roughly 1.3× quicker than TransFusion, despite the accuracy boost. Compared to older point-level fusion baselines such as PointPainting and MVP, BEVFusion not only delivered nearly 4% higher mAP but also ran with about 1.6× less latency. The gains come from preserving the full image feature map instead of throwing away most pixels, which means it can use smaller input images, cut compute, and still improve detection performance. Fusing in BEV space, in other words, proves to be both more accurate and more efficient.
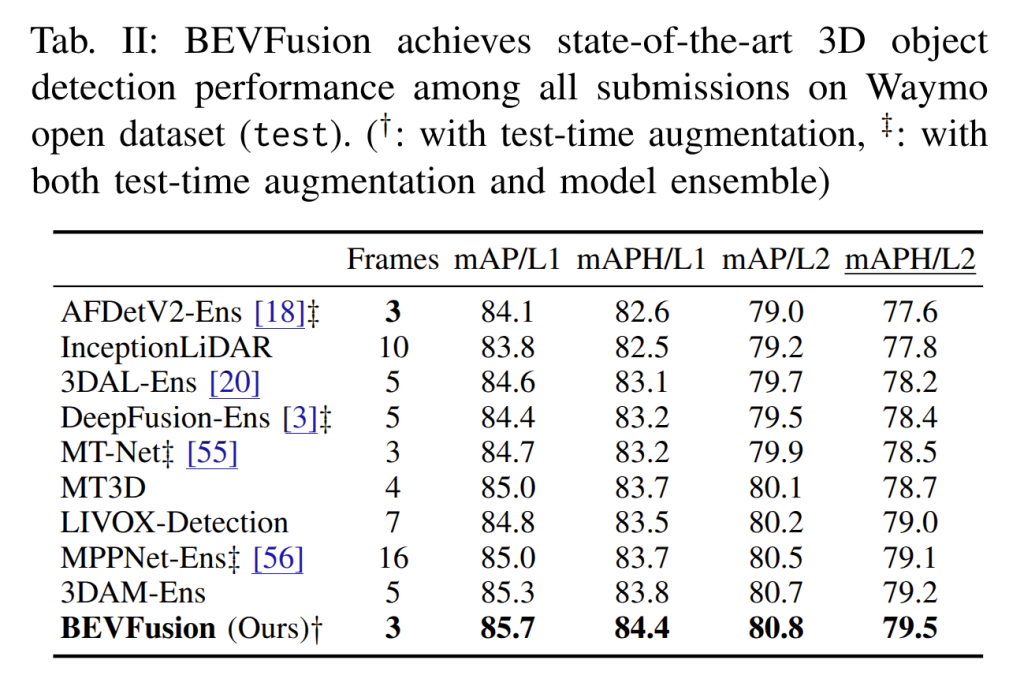
The model also delivered on the much larger Waymo Open Dataset. Using just a single model and three LiDAR frames as input, BEVFusion reached 85.7% mAP (L1) and 84.4% mAPH (L1), outperforming every prior published method. Remarkably, it even beat DeepFusion, a 2022 approach that had ensembled 25 models with heavy test-time augmentation, all while using fewer input frames. This result highlights just how effective BEVFusion’s fusion design is. In fact, the paper shows it topping the Waymo 3D detection leaderboard among multi-modal methods, ahead of far more resource-intensive entries. Taken together, results on both nuScenes and Waymo make it clear: BEVFusion is a new state of the art for 3D object detection, combining higher accuracy with lower computational cost than any previous camera-LiDAR fusion approach.
BEV Map Segmentation Performance
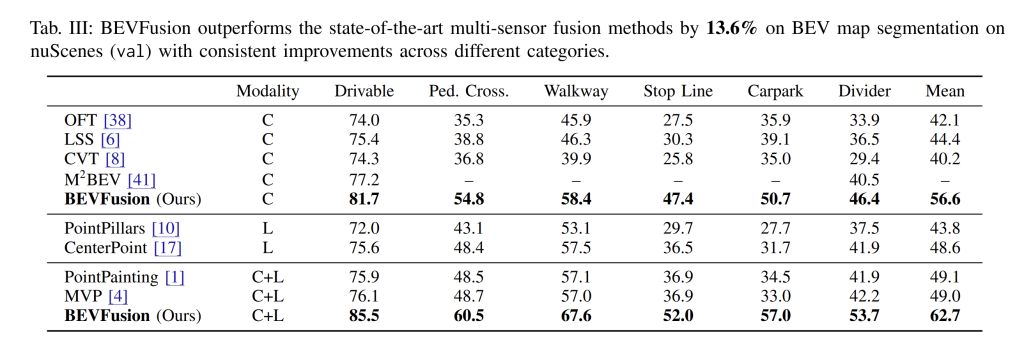
Perhaps even more impressively, BEVFusion shines in BEV map segmentation – a task that previous fusion methods struggled with. nuScenes provides a map segmentation benchmark (predicting drivable areas, crossings, lanes, etc. in the surrounding 100 m² region). This task is highly semantic-oriented, and methods that rely too heavily on LiDAR tend to perform poorly (since LiDAR can’t capture painted lines or texture well). BEVFusion, thanks to its dense camera feature integration, achieves a new state-of-the-art on this task by a large margin. According to the paper, BEVFusion’s multi-modal model reaches 62.4% mIoU (mean IoU across 6 classes) on nuScenes, which is +13.6% higher than a LiDAR-only model and about +6% higher than a camera-only model. In fact, prior fusion baselines “hardly work” for BEV segmentation – many object-centric fusion methods achieved little to no improvement over using LiDAR alone. By contrast, BEVFusion leverages both modalities to excel at both geometry and semantics: the camera provides context to label road features, while LiDAR provides precise range and alignment.
It’s insightful to break down these results. The authors report that a camera-only BEV segmentation model (essentially BEVFusion without LiDAR) already outperforms a LiDAR-only model by 8-13 mIoU on this task. This reverses the usual trend seen in detection (where LiDAR outperforms cameras by ~20 points of mAP). In multi-modal form, BEVFusion further improves by +6 mIoU over the camera-only variant and over +13% mIoU compared to state-of-the-art point-level fusion methods like PointPainting or MVP. In other words, BEVFusion not only provides a way to fuse sensors – it is inherently a superior architecture for semantic BEV understanding. The paper attributes this to the fact that previous fusion methods were object-centric and designed for detection: they only augment features for discrete objects or foreground points. Those approaches contribute little to segmenting continuous map elements (lane markings, road regions). BEVFusion, by fusing whole images into BEV, treats the entire scene (foreground and background) with equal importance. This leads to substantial improvements in mapping out the scene – an area critical for planning in self-driving. Table III of the paper quantitatively confirms these gains, marking BEVFusion as the first fusion model to convincingly handle BEV segmentation.
Robustness Under Various Conditions

One of the biggest promises of multi-sensor fusion is robustness: if one sensor struggles, the other can cover for it. The BEVFusion paper digs into this idea, analyzing performance under different conditions like lighting, weather, distance, and LiDAR sparsity. Across the board, BEVFusion proves more reliable than single-modality models or earlier fusion approaches.
Lighting is a clear example. Cameras lose reliability at night, while LiDAR is unaffected by darkness. In these cases, BEVFusion leans on LiDAR geometry and delivers a big boost: over 12 mIoU better than the best vision-only model in low light. For detection too, it outperforms vision-heavy fusion baselines, which falter when 2D cues break down in the dark.
In rain, the opposite problem arises. LiDAR data becomes noisy, but cameras still capture object appearance well. BEVFusion shifts the load to vision and gains more than 10 mAP over a LiDAR-only baseline, narrowing the gap between clear and rainy conditions.
The benefits also show up with small or distant objects. Sparse LiDAR struggles here, but dense image features fill the gap. BEVFusion clearly improves detection of tiny objects and keeps its edge as distance increases, especially past 30 meters where LiDAR density drops off. Competing methods like MVP barely help in these cases because they only decorate points rather than fully leverage the image.
Finally, the paper tests extreme LiDAR sparsity, simulating low-cost sensors with just 16, 4, or even 1 beam. BEVFusion maintains strong accuracy, beating MVP by around 12 NDS in the 1-beam case, where MVP collapses. And it does so with less compute, since it doesn’t need to hallucinate extra points.
Altogether, these results show that BEVFusion makes the most of each modality. It relies on LiDAR geometry in the dark, vision in the rain, and combines both for small or far-off targets. The shared BEV space is what makes this possible, giving both sensors a common ground to reinforce one another. For safety-critical tasks like self-driving, this kind of balanced reliability is exactly what fusion is meant to deliver.
Conclusion
BEVFusion marks a shift in how multi-sensor fusion is done for autonomous driving. Rather than forcing one modality into the other’s frame, it unifies both in the bird’s-eye view, a space that naturally suits most 3D perception tasks. The architecture is simple, modular, and task-agnostic, making it easy to extend while avoiding the heavy tuning seen in older pipelines.
Its results speak for themselves: state-of-the-art accuracy on both nuScenes and Waymo, achieved with a single lightweight model that is faster and more efficient than prior methods. Since its release, BEVFusion has already influenced subsequent research, been integrated into open-source codebases, and found its way into practical driving stacks.
In the end, BEVFusion demonstrates that BEV is the right common ground for fusing vision and LiDAR by retaining the strengths of both while enabling robustness across conditions. It stands as a strong baseline for future work in sensor fusion and multi-task perception.


