

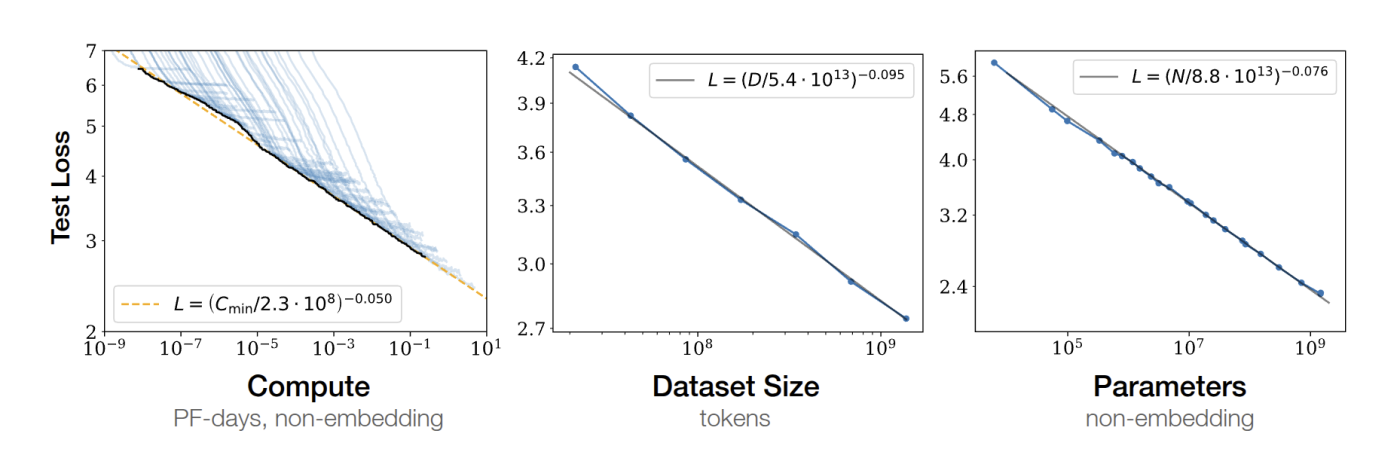
Introduction Scaling up machine learning models – in terms of model size, dataset size, and compute – has led to dramatic improvements in performance on language and vision tasks. In recent years, researchers have observed striking neural scaling laws: empirical relationships showing that as we
Motivation Autonomous vehicles rely on different sensors (cameras, LiDAR, and radar) each offering a unique view of the world. Combining them is key to reliable perception, but it’s tricky because cameras capture 2D images while LiDAR gives 3D structure. Earlier methods tried to force one
Robots in unstructured spaces, such as homes, have struggled to generalize across unpredictable settings. In this context, a few projects stand out more than the rest – for example, the Everyday Robot project at Google X and Figure’s 01 home robot. After being tied to
Let’s talk about DINOv2, a paper that takes a major leap forward in the quest for general-purpose visual features in computer vision. Inspired by the success of large-scale self-supervised models in NLP (think GPTs and T5), the authors at Meta have built a visual foundation
DeepSeek-V2 introduces a major architectural innovation that enhances its efficiency as a language model – Multi-Headed Latent Attention (MLA). MLA stands out as a game-changing technique that significantly reduces memory overhead while maintaining strong performance. In this post, we will explore the fundamental concepts behind
Scaling Supervision Instead of the Architecture Depth Anything doesn’t try to win monocular depth with a clever new backbone. It asks a simpler question: if you can cheaply manufacture supervision at Internet scale, can a very plain recipe become a foundation model? The authors pair
Hey folks, welcome to another weekend! I love drones, they give us new perspective to look at the world around us. These machines possess the ability to traverse all three dimensions, traversing vast distances in any desired direction to fulfill our desires. Among the illustrious
Boston Dynamics’ Spot robot is something that has always fascinated me. But the price tag of $75000 is hard to digest considering I’m just a regular guy. Luckily, folks at SpotMicroAI had started designing the Spot Micro – an open-source project where anyone could 3D
Historically, we humans have developed models to understand our world. For example, Newton’s second law of motion gives us the equation F=ma, which tells us that a force ‘F’ applied to a static free body in space of mass ‘m’ would accelerate it with amount
Hey folks! I’m thrilled to share with you a research paper that I’ve been working on, diving deep into the fascinating realm of vision-based navigation for indoor robots. In my research paper titled “Real-time Vision-based Navigation for a Robot in an Indoor Environment”, I explore












Sagar Manglani
manglanisagar@gmail.com
Blogger
I write articles on computer vision and robotics.
